

An invitation to participate in the doctoral thesis of researcher Talal Muhammad Mishal, Department of Information Systems
Announcing a free online seminar on artificial intelligence technologies on the Scopus platform entitled “Leverage GenAI in your Research: Explore Scopus AI”

يعلن اتحاد الجامعات العربية بالتعاون مع بنك المعرفة المصري واتحاد مجالس البحث العلمي وELSEVIER
عن عقد ندوة مجانية عن بعد حول تقنيات الذكاء الاصطناعي على منصة "سكوبس"
بعنوان Leverage GenAI in your Research: Explore Scopus AI”"
وذلك في تمام الساعة 2:00 ظهرا في توقيت مكة المكرمة بتاريخ 4/9/2024.
مع أطيب تمنياتنا بدوام التوفيق والنجاح

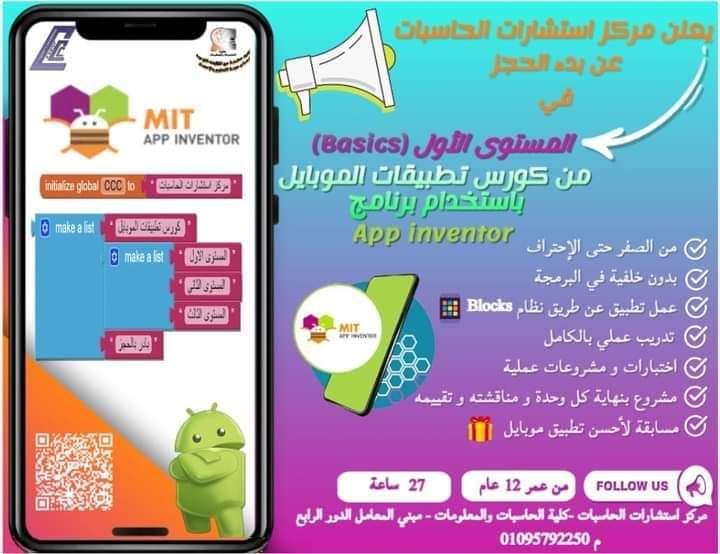
An interesting programming course for children App inventor

Important warning
It will begin, God willing, next Sunday, August 11, 2024
An interesting programming course for children App inventor
From nine in the morning until twelve in the afternoon
On Sundays, Tuesdays and Thursdays every week for three weeks
Anyone wishing to join must pay the fees quickly before the reservation door closes...there are limited places remaining ?
For reservations and inquiries / Assiut University - Faculty of Computers and Information Consulting Center - Laboratories Building, fourth floor
M/01095792250
The Faculty of Computers and Information at Assiut University announces the opening of applications for enrollment in master’s and doctoral programs for the first semester on the credit hour system for the academic year 2024/2025 in the period from 8/15/2


The Faculty of Computers and Information at Assiut University announces the opening of applications for enrollment in professional diplomas in information technology (a special program with fees) for the first semester on the credit hour system for the ac


Master's and doctoral programmes
The Faculty of Computers and Information at Assiut University announces the opening of applications for enrollment in master’s and doctoral programs for the first semester in the credit hour system for the academic year 2024/2025 in the period from 8/15/2024 to 9/15/2024 AD.
news category
Postgraduates
The Computer Consulting Center announces the start of reservations for the first level of the mobile applications course using the App Inventor program
An invitation to attend the closing ceremony of activities and Graduation Day for students of the College of Computing and Information, Class of 2024

International programming competition
 تحت رعاية معالي الوزير السيد أ.د/ أحمد المنشاوي رئيس جامعة أسيوط
تحت رعاية معالي الوزير السيد أ.د/ أحمد المنشاوي رئيس جامعة أسيوط
ا.د/ أحمد عبدالمولى نائب رئيس الجامعة لشئون التعليم والطلاب
أ.د/ تيسير حسن عبدالحميد عميد كلية الحاسبات والمعلومات – جامعة أسيوط
أ.د/ خالد فتحي حسين وكيل الكلية لشئون التعليم والطلاب
د/ ماجد أحمد جاد الرب عسكر رائد أسرة البرمجة بالكلية
يشارك طلاب كلية الحاسبات والمعلومات – جامعة أسيوط لأول مره في المسابقة الدولية للبرمجة Icpc international programming contest والتي تقام لأول مره بجمهورية مصر العربية في الفتره من 14 وحتى 18 أبريل 2024م .
تعد هذه المسابقة أكبر وأشهر مسابقة دولية على مستوى العالم وتشاك بها أشهر جامعات العالم وتتنافس فيها أفضل العقول بالعام كله وتستضيف المسابقة أكثر من 2500 شاب وفتاه من المتساقين ومدربينهم على مستوى العالم من الدول لعربية والأجنبية يمثلون 2000 جامعة حول العالم من 111 دولة من طلاب وأعضاء هيئة تدريس وشركاء دوليين لصناعة البرمجيات العالمية .
يشارك في المسابقة الطلاب والخريجين :
الفريق الأول : فريق الأحلام
• أحمد عزت صابر علي (دراسات عليا )
• أحمد ياسر فاروق ( المستوى الرابع)
• محمود عبدالكريم محمد (دراسات عليا)
الفربق الثاني : Attack_on_ICPT
• محمود صلاح سيد عاشور المستوى الرابع
• أحمد خالد أحمد عبد المعبود المستوى الرابع
• محمد أحمد حسن شحاته المستوى الرابع
مدربين الفرق : م/ حسين إبراهيم ، م/ أيمن صلاح (خريجي كلية الحاسبات والمعلومات – جامعة أسيوط)
جامعة أسيوط)
