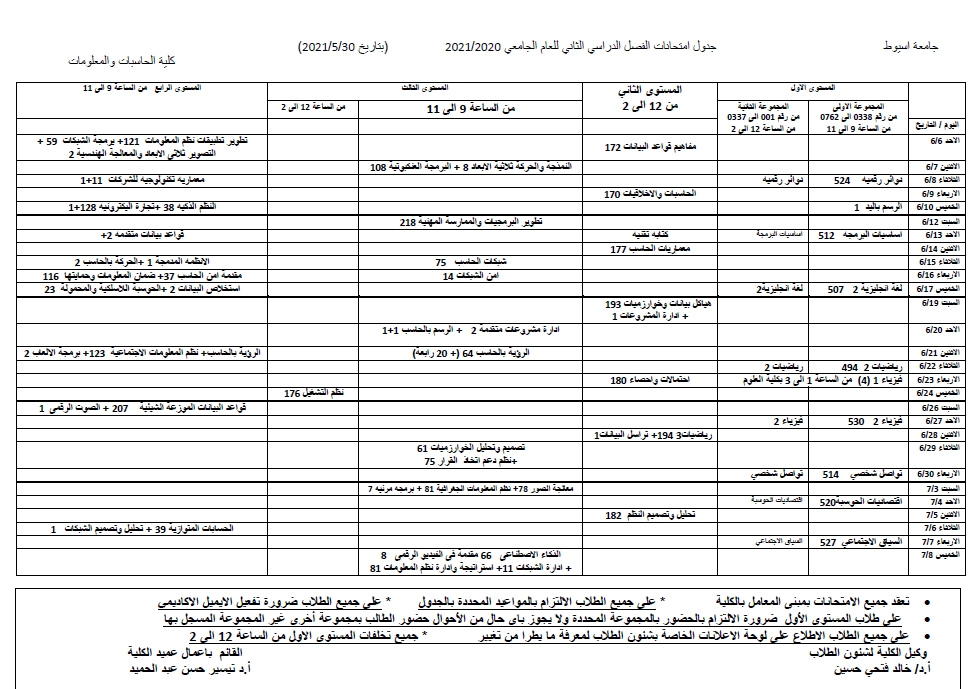
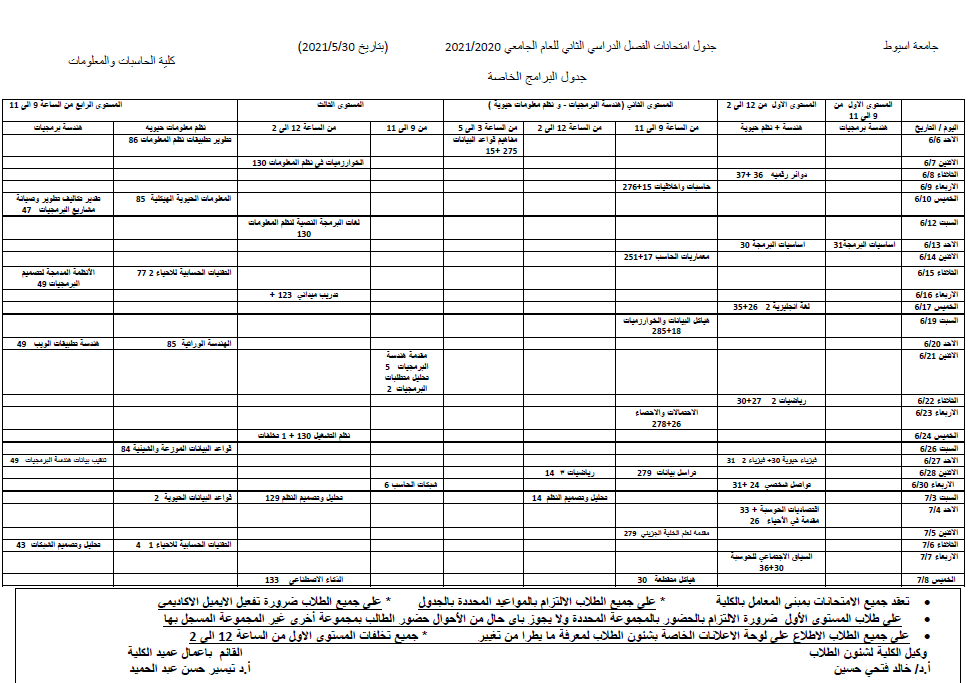
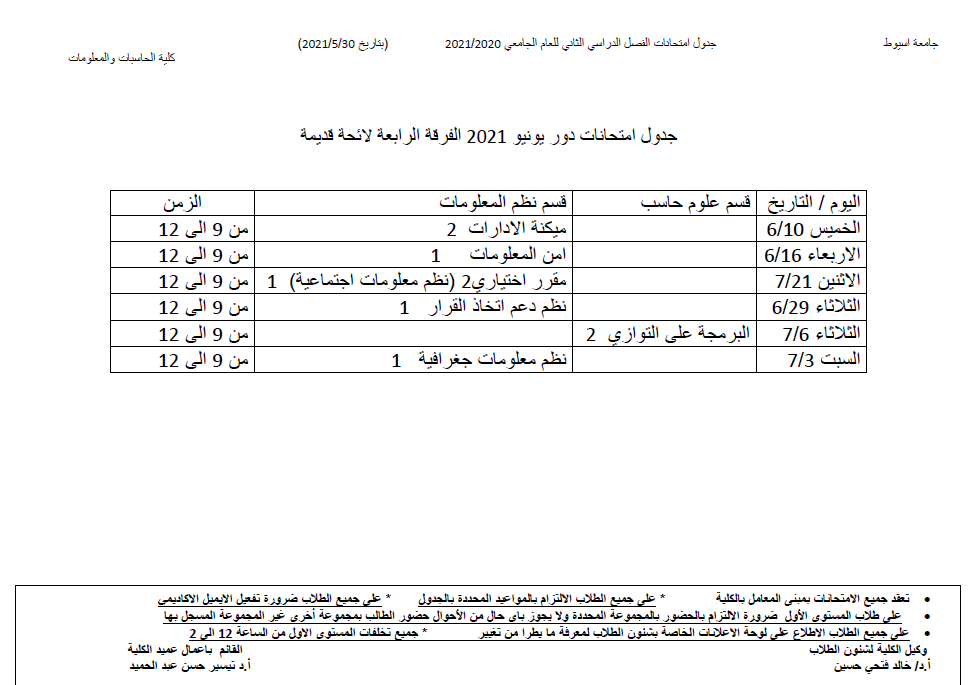
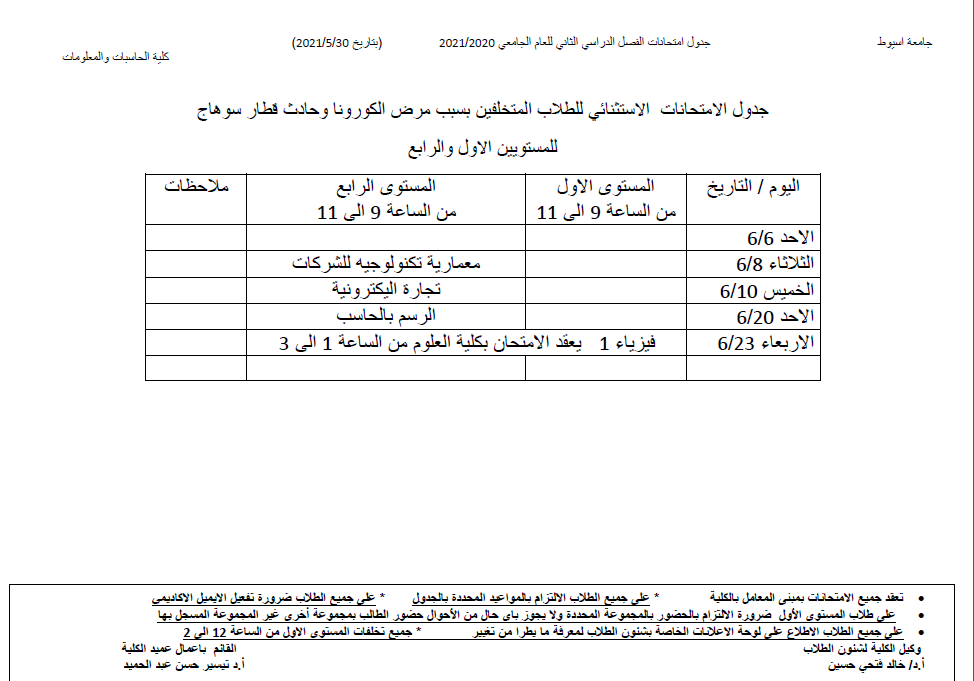
Reversible Color Image Watermarking Using Fractional‑Order Polar Harmonic Transforms and a Chaotic Sine Map
Watermarking of digital images is a well-known technique that is widely used for
securing image contents. A successful watermarking method must be accurate,
reversible, resilient, and robust against various attacks. In this paper, we propose a
reversible and robust color image watermarking method. A new set of multi-channel
fractional-order polar harmonic transforms and their geometric invariants have been
derived. These highly accurate and geometrically invariant features are used in the
watermarking process. The binary watermark’s bits were scrambled using a 1D chaotic
sine map to increase the security level. A set of experiments were performed
to evaluate the proposed watermarking method, and its performance was compared
with recent color image watermarking methods having similar colors. The obtained
results showed high visual imperceptibility and superior robustness against geometric
and signal processing attacks.