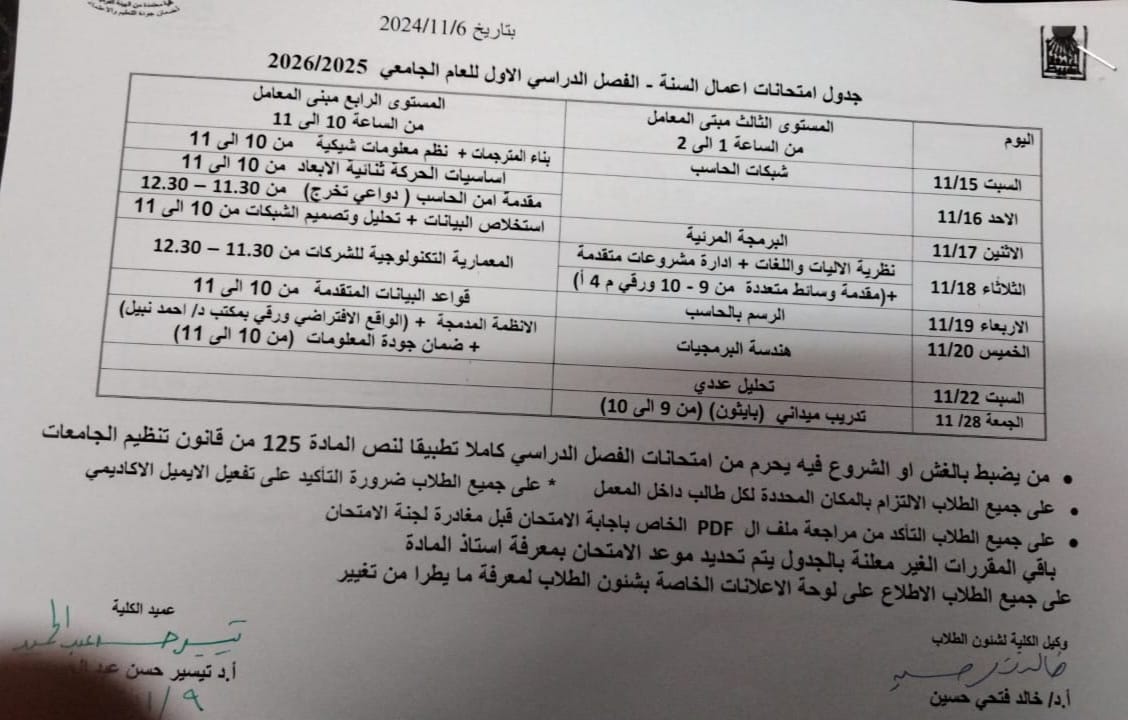
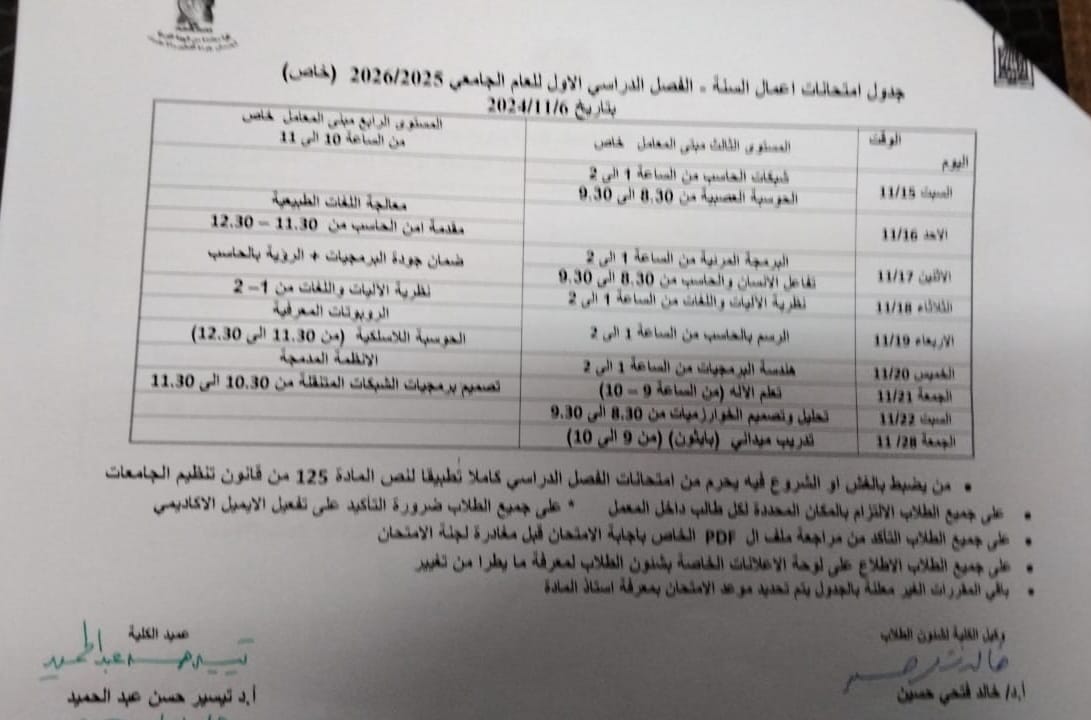
Schedule of mid-year exams, first semester 2025/2026 (private)
The ITIDA Job Fair
A great opportunity for all graduates and students in Assiut!
The ITIDA Job Fair is coming to Silicon Oasis Assiut (Smart Village) on November 25th ?
This event will open new doors to the world of work!
Meet companies from the Tech, Software, and Call Center sectors,
and take the first real step towards your professional future
. Don't miss this opportunity! ?
? Attendance is free and open to everyone.
? Silicon Oasis Assiut (Smart Village) ? November 25th
? Free transportation provided
Register now using this link
Alaa E Abdel-Hakim, Abdel-Monem M Ibrahim, Kheir Eddine Bouazza, Wael Deabes, Abdel-Rahman Hedar
Research Abstract
Traditional K-means clustering assumes, to some extent, a uniform distribution of data around predefined centroids, which limits its effectiveness for many realistic datasets. In this paper, a new clustering technique, simulated-annealing-based ellipsoidal clustering (SAELLC), is proposed to automatically partition data into an optimal number of ellipsoidal clusters, a capability absent in traditional methods. SAELLC transforms each identified cluster into a hyperspherical cluster, where the diameter of the hypersphere equals the minor axis of the original ellipsoid, and the center is encoded to represent the entire cluster. During the assignment of points to clusters, local ellipsoidal properties are independently considered. For objective function evaluation, the method adaptively transforms these ellipsoidal clusters into a variable number of global clusters. Two objective functions are simultaneously optimized: one reflecting partition compactness using the silhouette function (SF) and Euclidean distance, and another addressing cluster connectedness through a nearest-neighbor algorithm. This optimization is achieved using a newly-developed multiobjective simulated annealing approach. SAELLC is designed to automatically determine the optimal number of clusters, achieve precise partitioning, and accommodate a wide range of cluster shapes, including spherical, ellipsoidal, and non-symmetric forms. Extensive experiments conducted on UCI datasets demonstrated SAELLC’s superior performance compared to six well-known clustering algorithms. The results highlight its remarkable ability to handle diverse data distributions and automatically …
Research Date
Research Department
Research Journal
Algorithms
Research Member
Research Pages
https://scholar.google.com/scholar?oi=bibs&cluster=1136932969198565742&btnI=1&hl=en
Research Publisher
MDPI
Research Vol
Volume 17, Issue 12
Research Website
https://scholar.google.com/scholar?oi=bibs&cluster=1136932969198565742&btnI=1&hl=en
Research Year
2024
Dynamic Deployment of Mobile Roadside Units in Internet of Vehicles
Research Abstract
Mobile roadside units have crucial role in ensuring efficient communication, computing, and caching services in internet of vehicles (IoVs) for vehicles traversing urban landscapes. The dynamic nature of urban environments faces challenges in optimizing the deployment of mRSUs to adapt to varying vehicular densities and traffic patterns in real-time. In this article, we propose a novel real-time optimization approach for the dynamic deployment of mobile Roadside Units (mRSUs) in urban environments to support the rapid growth of the IoV. The proposed method is a novel allocation strategy based on Minimum Dominating Set (MDS) theory, which is demonstrated to significantly reduce the number of mRSUs required. This reduction is achieved without compromising the efficiency and effectiveness of the network, thereby ensuring rapid and reliable communication within the IoV. This approach addresses critical …
Research Date
Research Department
Research Journal
IEEE Access
Research Member
Research Pages
155548-155534
Research Publisher
IEEE
Research Vol
12
Research Website
https://scholar.google.com/scholar?oi=bibs&cluster=9429625967726641888&btnI=1&hl=en
Research Year
2025
Announcement of an awareness seminar on combating drugs among students

Congratulations to the student Diab Saudi Diab for achieving fourth place in the annual major religious competition.

Congratulations to student Reem Ahmed Abdel Aal for winning first place in the religious competition.

Congratulations to student Yahya Ayman Muhammad for winning third place in the annual major religious competition.


The team from the Faculty of Computers and Information at Assiut University won third place in the African and Arab rankings in the world's largest programming competition for the fourth time.

Under the patronage of Professor Dr. Ahmed El-Menshawy, President of Assiut University,
Professor Dr. Ahmed Abdel-Mawla, Vice President for Education and Student Affairs,
Professor Dr. Tayseer Hassan Abdel-Hamid, Dean of the Faculty of Computers and Information,
Professor Dr. Khaled Fathy Hussein, Vice Dean for Education and Student Affairs,
and Dr. Magdy Gad El-Rab Askar, Lecturer in the Computer Science Department - Family Leader,
The Faculty of Computers and Information congratulates the Assiut University team for achieving third place in Africa and the Arab world in the world's largest programming competition, in which 139 universities and more than 70 countries participated.
ICPC World Finals 2025 in Azerbaijan Comes to an End!
Team Members:
Mohamed Reda
Abdelrahman Saad
Nourhan Hanna
Coaches:
Eng. Hussein Ibrahim
Eng. Ahmed Ezzat
Eng. Mahmoud Hamdy
Eng. Mohamed Shehata
Eng. Ahmed Alaa
This marks the fourth consecutive time that the Assiut University team has qualified for the international competition. We hope that Assiut University will be among the best teams and universities in the world in this international competition and consistently achieve top rankings among all countries.