Skip to main content
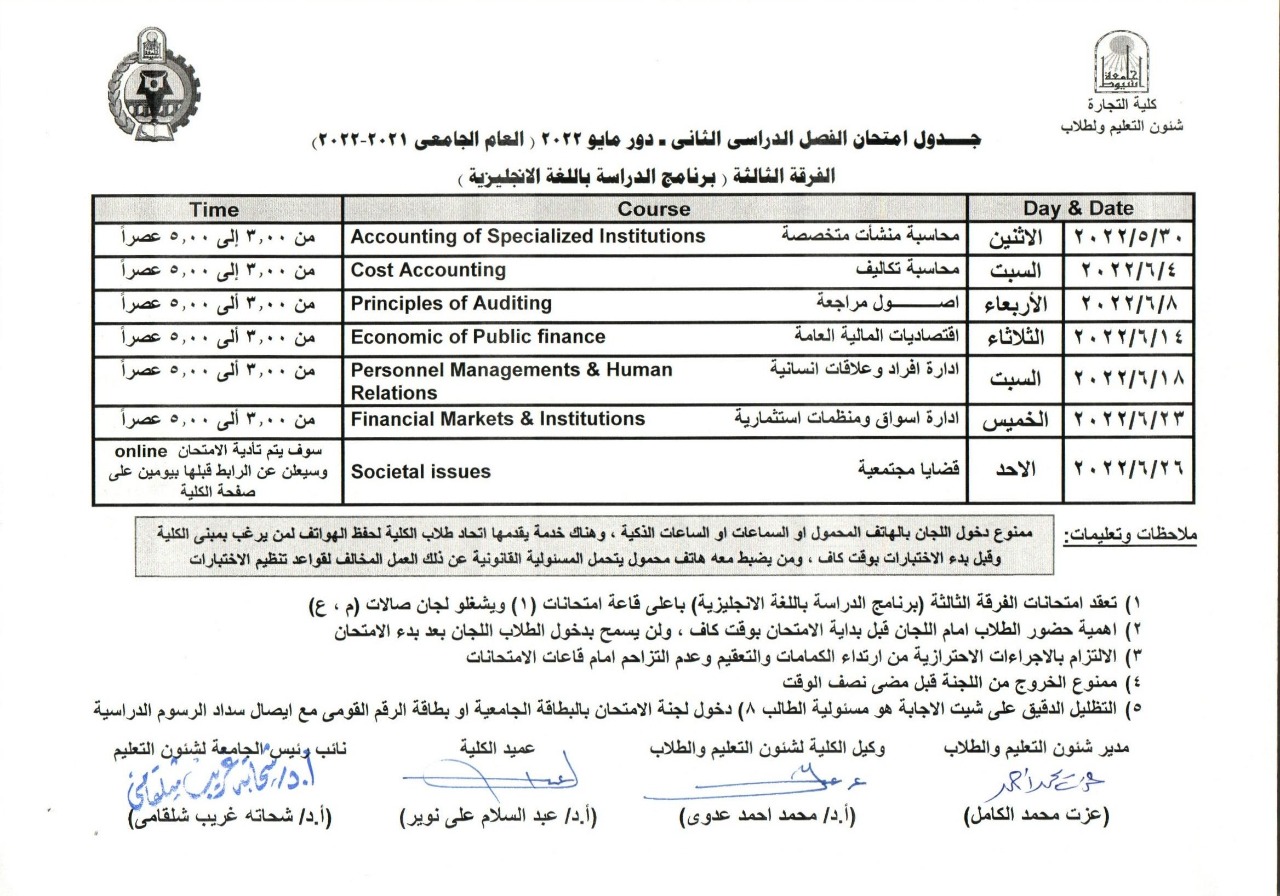
Third year exam schedule - second semester 2021/2022 (language)
Second year exam schedule - second semester 2021/2022 (language)
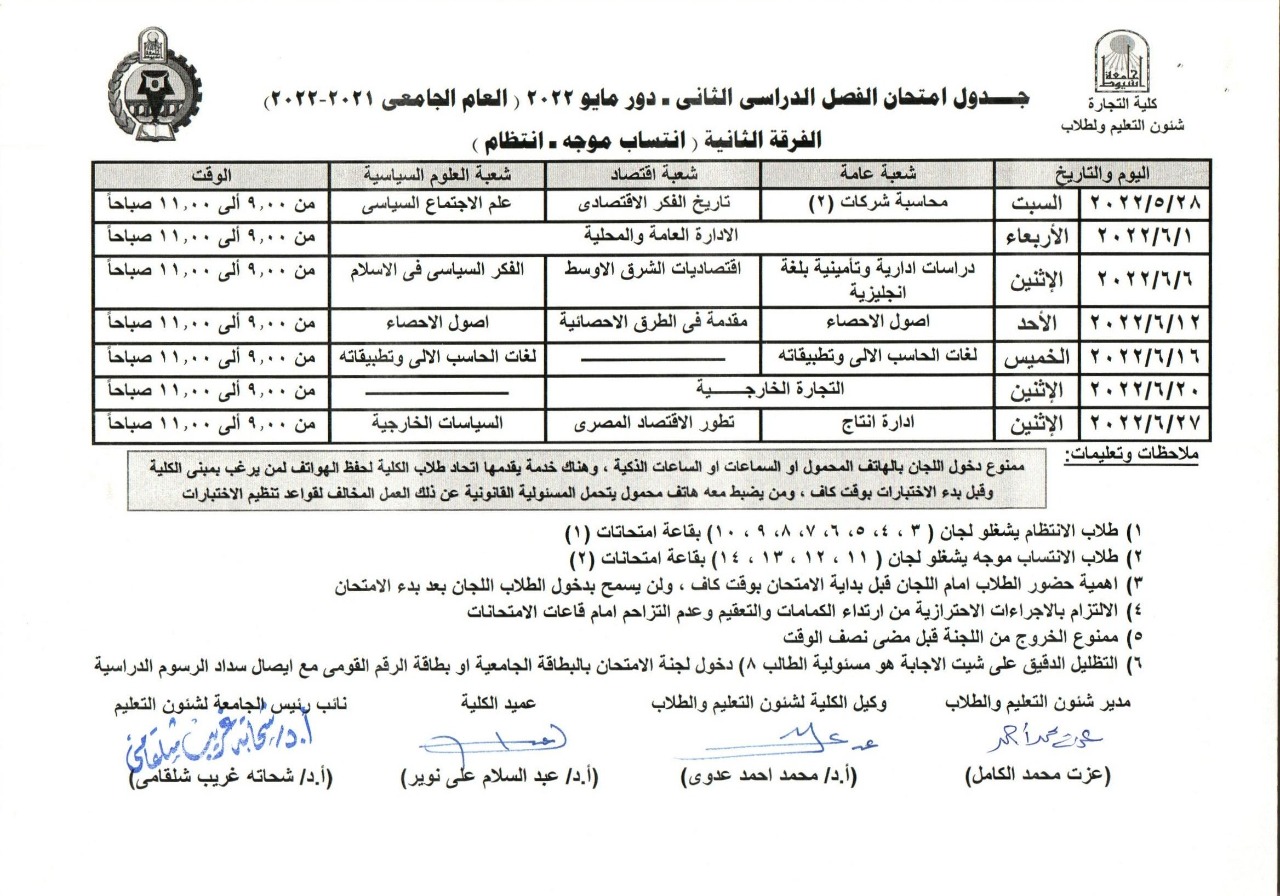
Second year exam schedule - second semester 2021/2022 (Arabic)
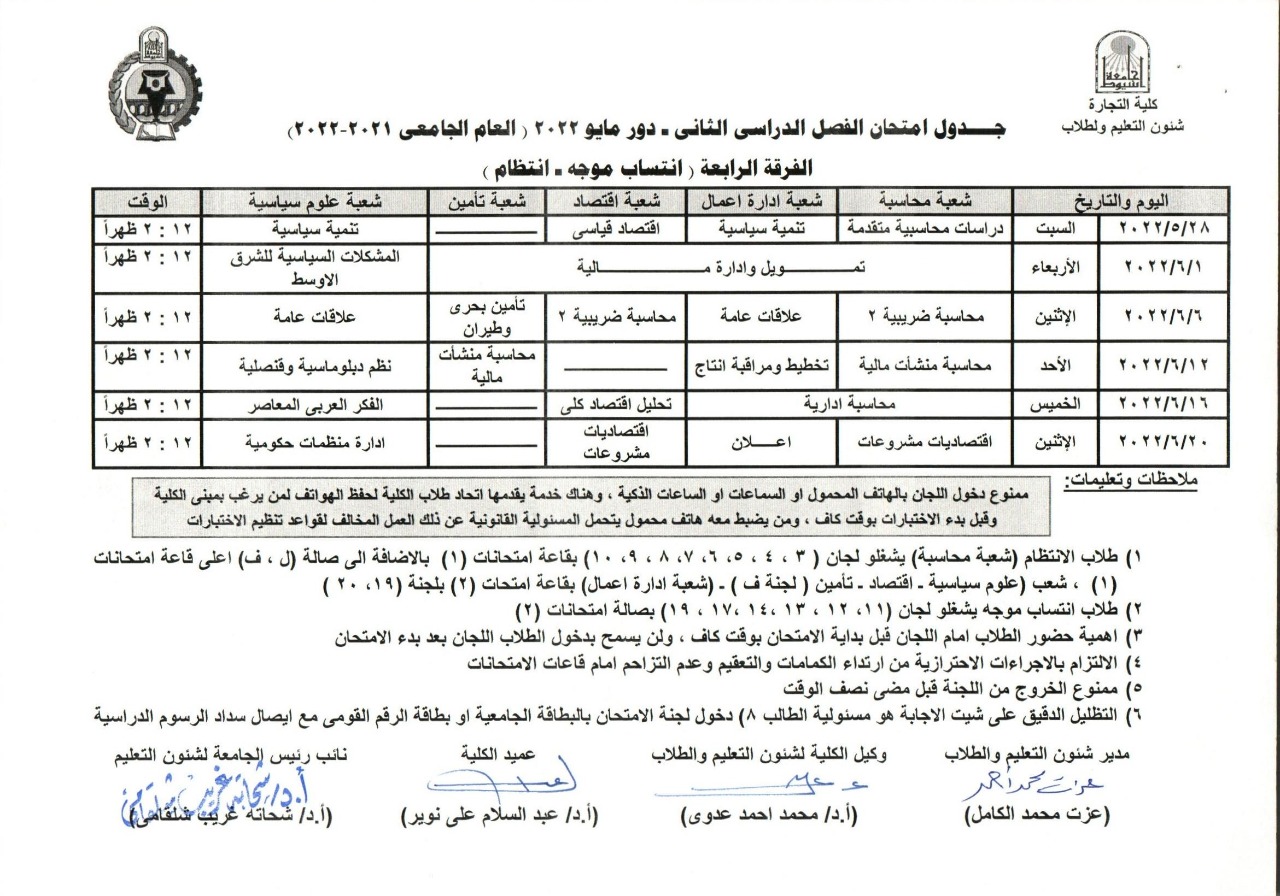
Fourth year exam schedule - second semester 2021/2022 (Arabic)
First year exam schedule - second semester 2021/2022 (Arabic)
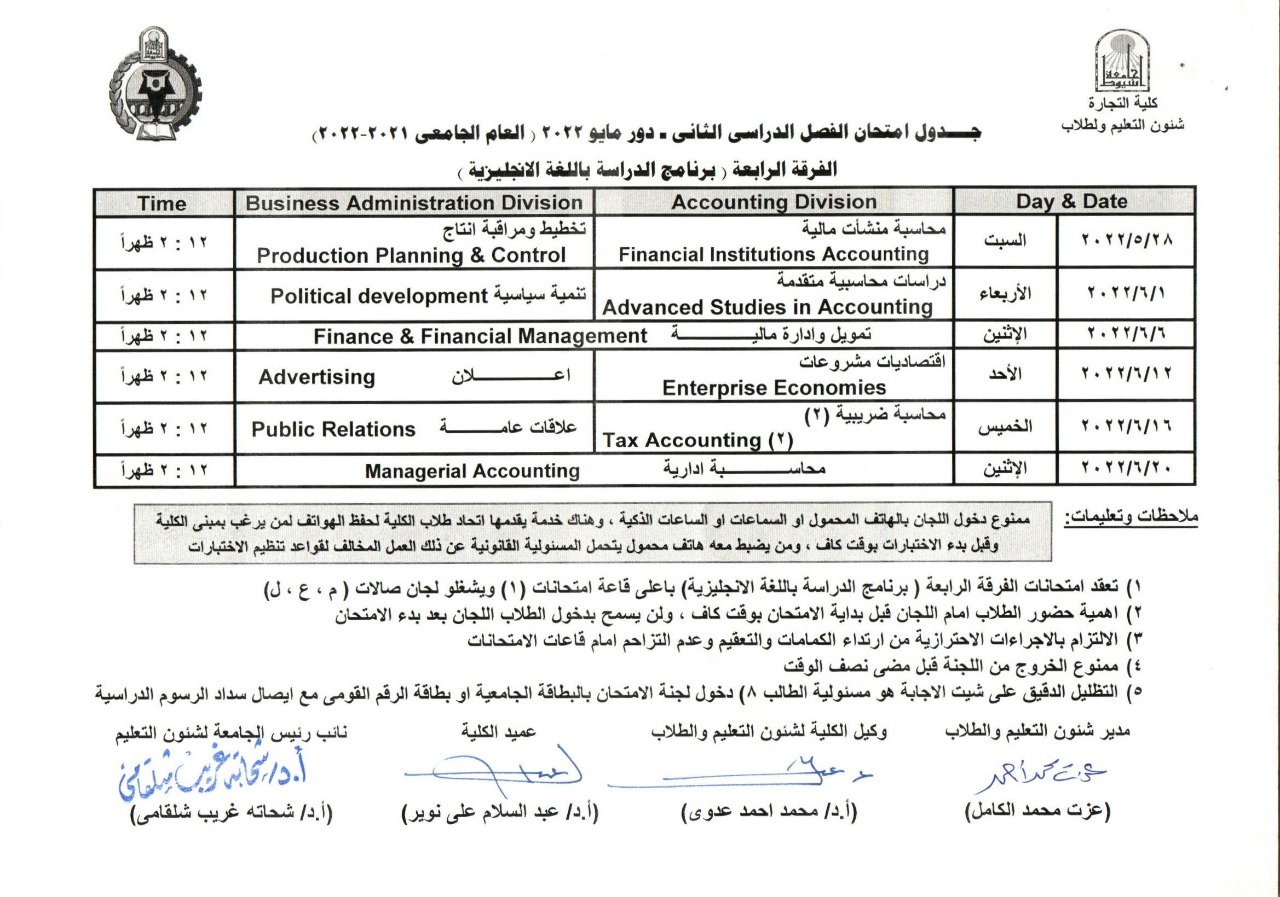
Fourth year exam schedule - second semester 2021/2022 (language)
Dates and procedures for candidacy for the position of President of the University
An important announcement from the Computer Center at the Faculty of Commerce regarding holding several training courses
Important announcement for third and fourth year students
Distribution of certificates for the free course for college students, which was held at the Computer Center at the College of Commerce
Subscribe to